Yet another AI article. It might be overwhelming at times. In this comprehensive guide, I’ll simplify the complex world of Generative AI, aiming to make modern, scalable AI stacks understandable for everyone.
AI has been on a remarkable journey since its inception in the 1950s, but the last decade has truly transformed the landscape. Unlike anything before, Generative AI has the astonishing ability to create images, text, and code that resemble human-like creations. However, to truly leverage its potential, a solid and well-integrated framework is essential. Let’s walk through its workings and how it can be applied in practical ways.
Table of Contents
- AI Fundamentals
- What’s underneath of Large Language Models(LLMs)?
- Guide on Learning AI
- Modern Gen AI Stack
- Key Elements of GenAI Stack
- Retrieval augmented generation or RAG
- Fine-tuning
- Future Trends in AI
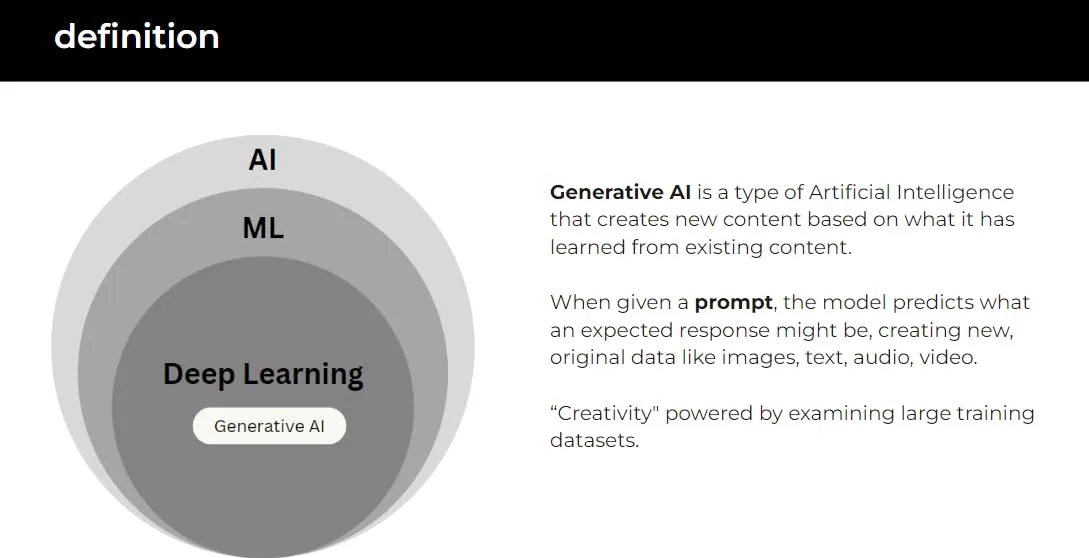
AI Fundamentals
The diagram above shows that deep learning is a subset of Machine Learning. Traditional ML algorithms mostly fall into either supervised learning — when you have the target labels to train the prediction model on; or unsupervised learning when there are no target labels.
It could be helpful to go over some ML jargon and get a high-level idea of popular ML algorithms. Since AI today uses Deep Learning, you can jump straight into DL. You will likely learn the essential ML concepts along the way, and you may fill in the gaps in your understanding if needed.
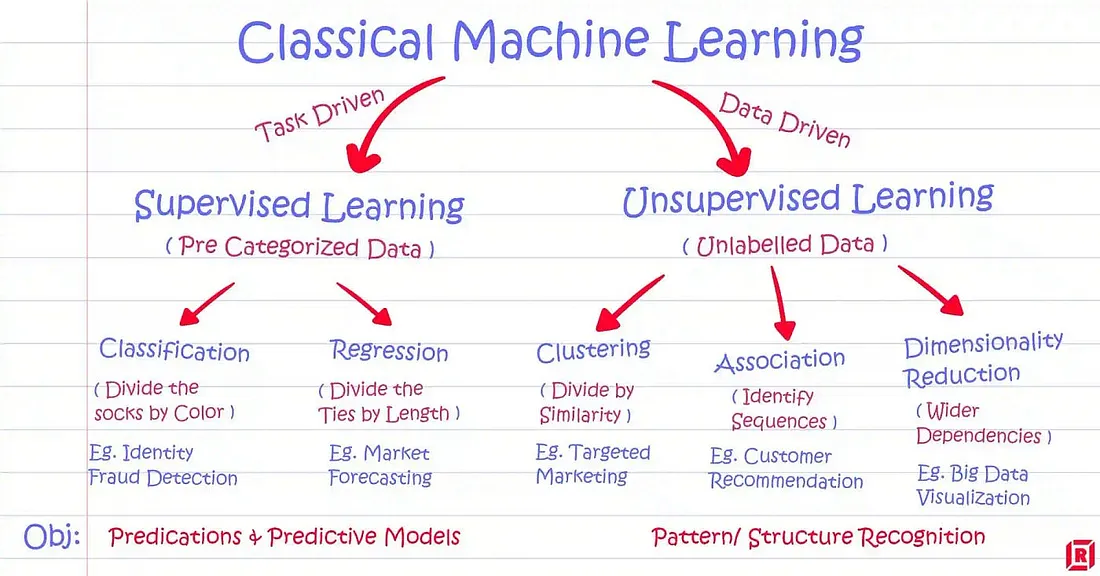
How Neural Networks Works
Neural networks are the algorithm behind deep learning, including Gen AI we see today. It works incredibly well for unstructured data like text and images. A neural network, in itself, is pretty simple and maybe even a bit inferior from the mathematical point of view. However, when you stack many network layers together into a certain complex architecture, surprisingly, they could do amazing stuff, from recognizing digits and classifying cats and dogs to pretty much anything you ask it to do in the case of LLMs (Large Language Models) nowadays.
CNNs for Images
Convolutional Neural Networks (CNNs) are layers that scan 2D input arrays like photos to identify visual patterns like texture, shapes, and objects. They are effective for tasks requiring spatial/image understanding.
RNNs for Text
Recurrent Neural Networks (RNNs) are connections that analyze sequences over time and retain key semantic meaning in long-form data like sentences. They are useful for contextual text modeling.
Both CNNs and RNNs are widely used for image and text processing, due to their ability to recognize patterns in images and understand sequences in text.
However, these architectures have quickly become obsolete since the invention of Transformers in 2017, which is the architecture behind large language models today. Transformers outperform earlier models, so you might want to skip learning the earlier architectures if you don’t have time.
Traditional ML vs Generative AI
Let’s understand the difference between them with a simple example. Discriminative technique refers to Traditional ML.
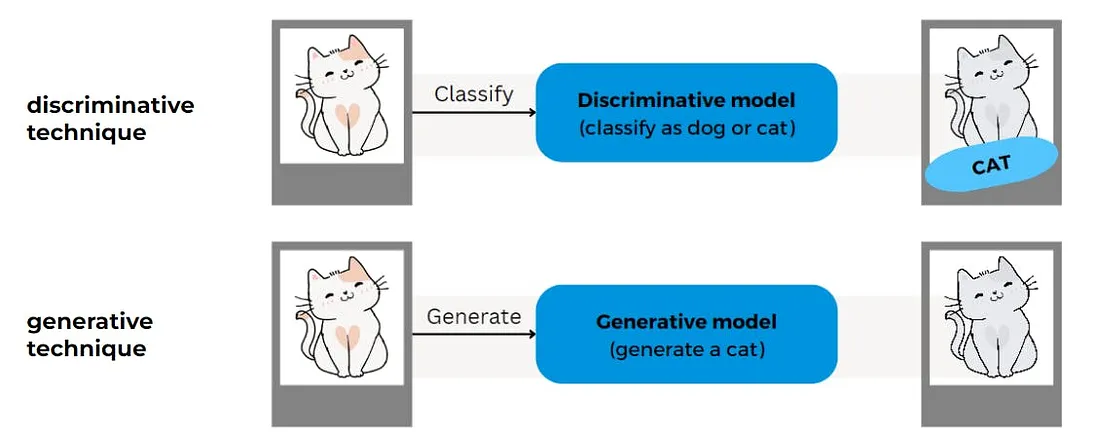
Discriminative models in Traditional ML are designed to classify or predict outcomes based on input data. They focus on drawing boundaries between different categories and making decisions.
- Examples: Predictive analytics in business forecasting, spam filters in email systems, and recommendation systems in streaming services.
In contrast, Generative AI doesn’t just analyze data; it creates new data that didn’t exist before.
- Examples: Creating new images, realistic human-like text
What’s underneath of Large Language Models(LLMs)?
LLMs navigate the complex language web through weights, parameters, and tokenization, giving responses based on vast data analysis.
Weights
Think model “expertise” assigned to certain words. These are numbers that make the model’s guesses better or worse. Bigger weights mean the guess is more likely. Like a word the model has seen used often before would have a bigger weight.
Parameters
Parameters are like options you configure. You can tweak all the settings to change how the model works overall. You could make it guess faster but be less accurate. You will have to set up the options yourself and consider matters like accuracy vs speed and other tradeoffs.
Tokenization
Cuts sentences into smaller pieces called tokens that the model takes in one by one. Words can be tokens. Or parts of words can be tokens. It’s like giving someone one Lego brick at a time to assemble instead of the whole set.
So, in simpler terms:
- Weights impact model outputs
- Parameters control model behavior
- Tokenization splits text into input units
Some examples:
- Weights: Guessing “brown” has a higher weight than “sqwerty” for the blank word
- Parameters: One of key parameters is “Temperature”. Low ‘temperature’ implies more predictable guesses closer to the training data, higher ‘temperature’ predicts more creative and risky, less factual outputs.
- Tokenization: Chopping “The quick fox” into [The] [quick] [fox] tokens
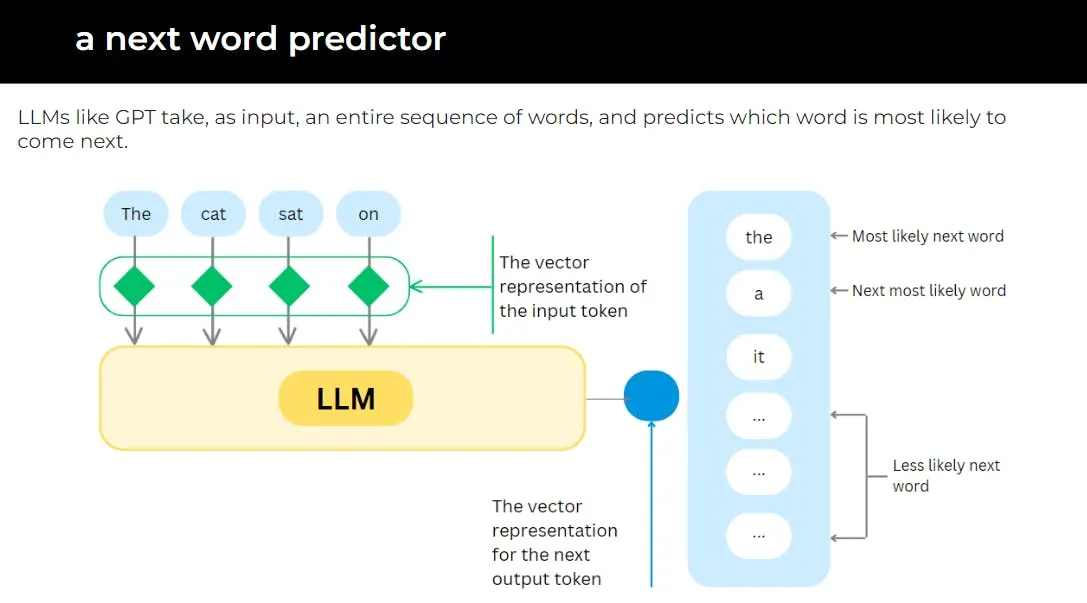
The model sees token inputs and guesses next tokens using weights, based on parameter settings. These are the core ideas behind how models like GPT work!
How Models Learn?
- Models start with random weights. As they process more text during training, the weights are gradually adjusted to better predict the next token.
- More data and bigger models lead to better performance, as shown by metrics like perplexity continuing to improve as model scale increases.
- Models don’t store or copy text. They simply update their internal weights to reflect associations and patterns seen, which aids their generation abilities.
Transformer Architecture
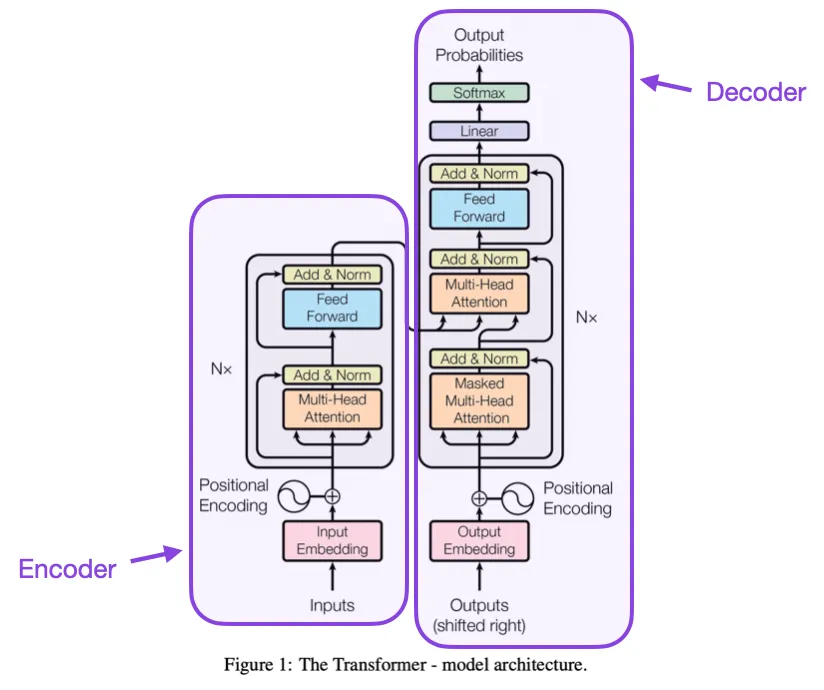
Transformers are the foundation for modern LLMs. These models are trained on large amounts of text data to generate and understand natural language. The transformer architecture consists of two parts:
- Encoder: Analyzes the input text by breaking it into smaller tokens, representing each token as a vector, and analyzing the relationships between the tokens to understand the overall meaning.
- Decoder: Generates output text, such as translations or summaries, based on the encoded representations from the encoder.
In LLMs, the Transformer Encoder deeply understands the input text, while the decoder generates new text as output. Pre-training and fine-tuning processes allow LLMs like GPT-3 to be adapted for different NLP tasks using the knowledge gained during pre-training. This transformer architecture is the core of modern LLMs like GPT-3, giving them impressive language understanding and generation abilities.
Guide on learning AI
Companies worldwide are racing to leverage the potential of AI, aiming to improve services and products. Large enterprises are eagerly adopting AI solutions to address their specific challenges. This presents a valuable opportunity, as the field is still relatively new.
However, like any emerging technology, AI models still face challenges. They are not yet fully reliable or stable and may exhibit biases, among other issues. You can make a significant impact if you possess the knowledge and skills to develop AI applications. Such knowledge can help avoid misunderstandings and misinformation, such as believing that “AI can do everything with the right plugins” ;)

Python & IDEs:
At a fundamental level, you want to learn the basics of programming. Python is the most used language for ML, making knowledge in Python essential. What’s nice about Python is that there are many open-source libraries and frameworks that you can use to develop almost anything you want, especially the ones focused on ML/AI. With Python, you can code a simple neural network using Numpy library to understand how it works. By learning Python programming and reading source code of open-source libraries, you can gain a good understanding of their functionality. To work with Python, you can use several IDEs (Integrated Development Environments):
- Replit
- VSCode
- Pycharm
- Jupyter Notebook
I primarily use Colab (basically Jupiter from Google), Replit, and PyCharm. They are completely free!
When learning Python, the most essential libraries are:
- Numpy for computing and working with numerical data.
- Pandas for wrangling tabular data, or dataframes.
- Matplotlib — Data visualisation
When you’re already familiar with those libraries, you can explore others.

I highly recommend these Python courses to gain a practical understanding:
- 100 day of code from Replit
- Python Data Science Toolbox from Datacamp
- Learn Python and Machine Learning for Everybody from FreeCodeCamp
- Python for Everybody Specialization (Coursera)
- Deeplearning.ai short programs
- Practical deep learning from Fast.ai
ML Learning Guide
I recommend watching Introduction to LLMs video by Andrej Karpathy to understand better the process behind training an LLM. Additionally, check out this video by Andrej Karpathy, as it demonstrates how to code a GPT from scratch if you want to get into details.
No matter where you are in your journey, you can build projects to gain hands-on experience and challenge your understanding. If you’re learning Python, build a neural network using libraries like Keras or Tensorflow. If you prefer theory, choose a concept that interests you and create a blog post or video about it. This will help you deepen your understanding and assist others too! For more advanced AI projects, create a real-world application. For example, run Langchain to build a document retrieval app or develop a specialized chatbot. Langchain is a very useful library in order to learn developing multiple applications on top of LLMs.
Remember to document your projects for future reference. You never know how many people may find them helpful!
ML Projects
Building a Chatbot with ChatGPT API and Reddit Data
Let’s Build GPT from scratch (Andrej Karpathy)
ML Learning
3Blue1Brown Neural Network playlist
Fast AI resources
CodeEmporium Transformers playlist
Deep Learning Specialization (Coursera/ Deeplearning.ai)
Deep learning book (Ian Goodfellow and Yoshua Bengio and Aaron Courville)
Natural Language Processing Specialization (Coursera/ Deeplearning.ai)
Git version control
The next thing I would recommend learning is Git version control. Git is an open-source software for tracking changes in your project.
Version control is essential when collaborating with others on large or complex projects. To start using Git, you only need to understand a few key concepts.
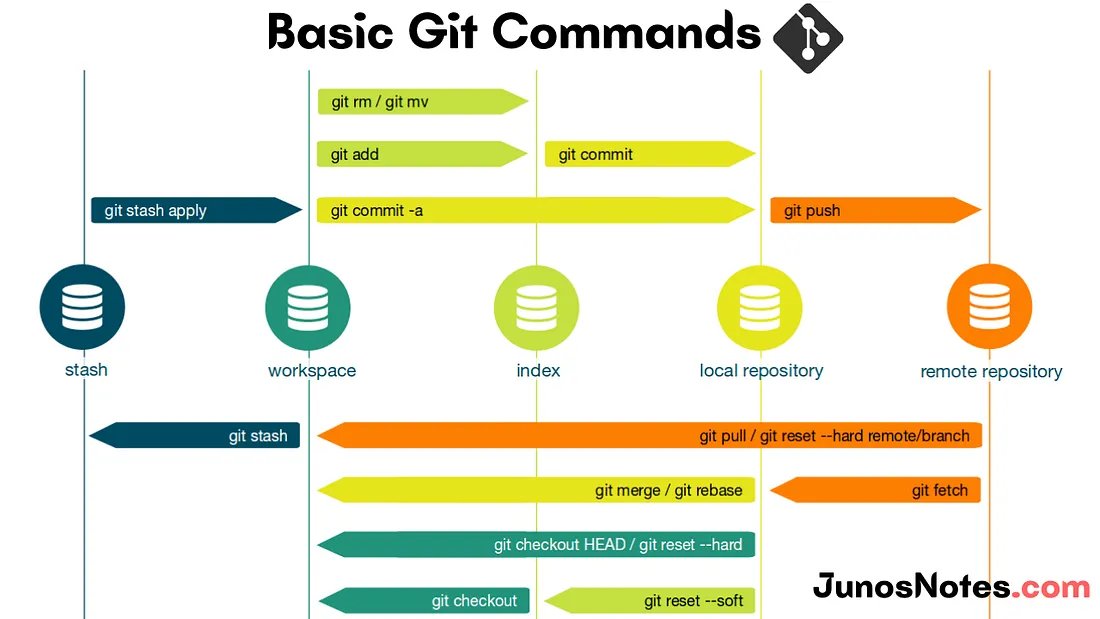
Many people often confuse Git with GitHub. GitHub is a hosting platform for Git repositories, allowing you to share your projects with others over the internet. On the other hand, Git refers to the software itself.
To start using Git, the easiest way is to use GitHub Desktop, which provides a user interface for Git. Alternatively, you can also use Git through the command line or terminal.
APIs
Another important concept to learn is APIs (Application Programming Interfaces). An API is a way for computer programs to communicate with each other. Key terms to understand:
- API request (also known as “API call”)
- API response
For example, when you scroll through your Instagram feed, you make API requests to the recommender model behind the Instagram app and receive responses in return.
Depending on the API, you can request data or model predictions (such as using the OpenAI API), among other things. Without knowing how to use an API, you would be limited to ChatGPT. While ChatGPT is a great way to use the GPT model, you cannot develop your tool or integrate GPT models into your existing system. To do so, you would need to use their model APIs.
Starting point
- Git book
- What is an API
- Git and Github crash course
- Git and Github for Beginners
Modern Gen AI Stack
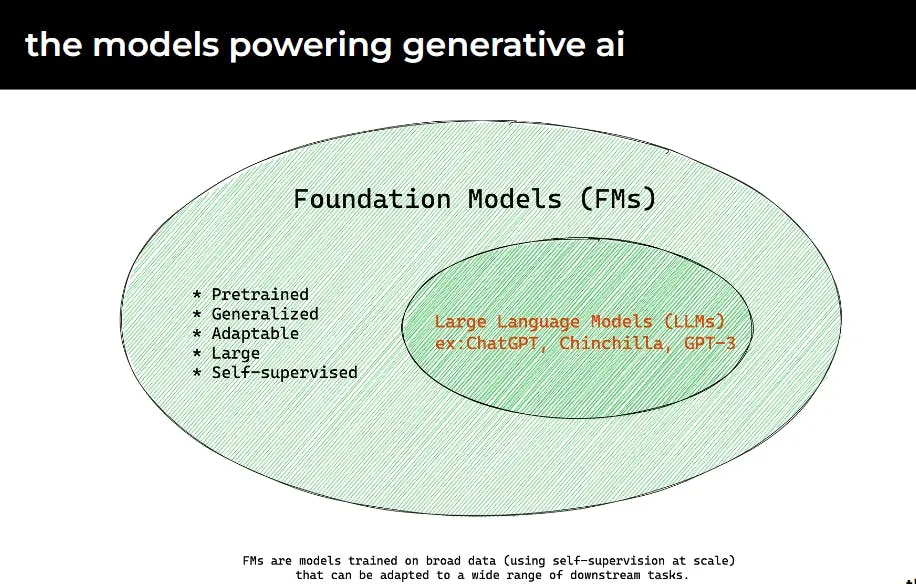
As you work with AI models, it’s important to have a high-level understanding of how the foundation models are trained. For instance, ChatGPT model from OpenAI utilizes GPT3 as its foundation model, but it also undergoes an additional training process called Reinforcement Learning from Human Feedback (RLHF).
Menlo Ventures highlighted 4 critical layers that make up a robust, modern Gen AI stack.

Compute + Foundation Models
This layer provides the computational resources needed to train and run AI models. It includes access to GPUs for intensive model training and inference and covers the foundation models. These foundation models are pretrained on massive datasets, providing a general set of capabilities that can then be tailored to specific tasks. Popular examples include models like BERT, GPT-3, and DALL-E.
Data Layer
This layer focuses on managing and processing data to feed into AI models. This involves Extract, Transform, Load (ETL) pipelines to pull data from different sources and wrangle it into a usable format. Vector databases are significant for handling complex unstructured data like text and images, encoding them into dense vector representations.
Deployment
This layer handles putting models into production and managing the lifecycle of AI applications. Turning a model into a usable application requires a robust deployment strategy. It covers the tools that enable the integration of AI models into production environments.
Observability
Once deployed, monitoring AI applications to ensure they perform as expected is vital. Observability enables monitoring the behavior and performance of models to detect issues.
Understanding GenAI Architecture
This includes data pipelines, training and inference engines for LLMs, model registries, deployment monitoring, and user interfaces. Tools like LangChain offer orchestration layers for rapid transitions from data to models to apps.
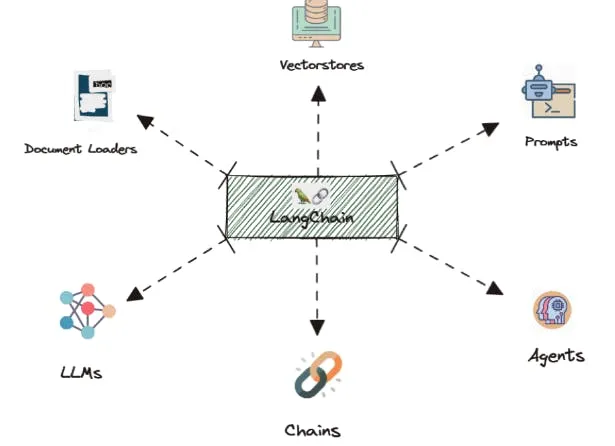
By understanding the modular, customizable architecture of today’s generative AI stacks, businesses can strategically build the right data and ML infrastructure. This will enable the deployment of value-driven AI applications.
Key Elements of GenAI Stack
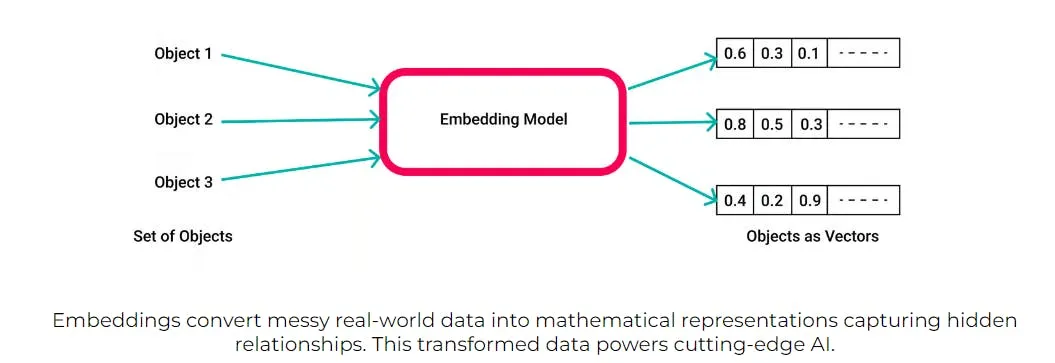
Embeddings
Numerical representations of data that can be used to train AI models. Embeddings are particularly useful for working with text data, as they can capture the semantic meaning of words and phrases. These transform high-dimensional data into lower-dimensional vectors, retaining essential information in a more manageable form.
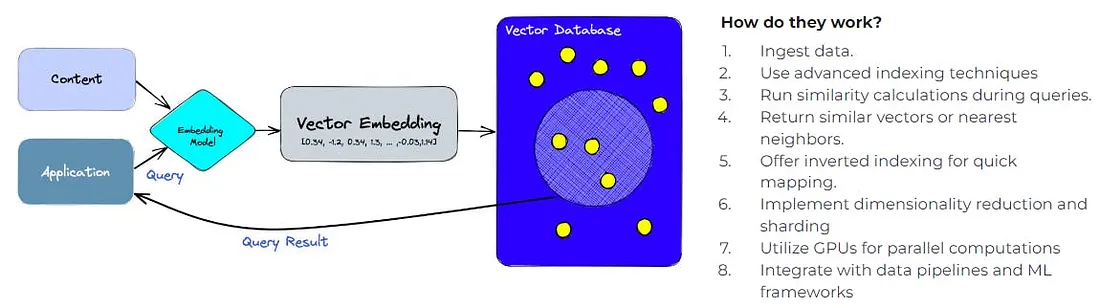
Vector Database
Stores and indexes vector representations for quick retrieval, supporting operations like vector search and similarity rankings, forming the backbone of vector infrastructure in AI.
LLMs and Prompts
At the core of generative capabilities, LLMs respond to prompts to generate text, making them essential for applications like content creation and customer service.
Making sense of embeddings and Vectors
We often forget that computers cannot actually understand language, only numbers. So, this conversion step is necessary.
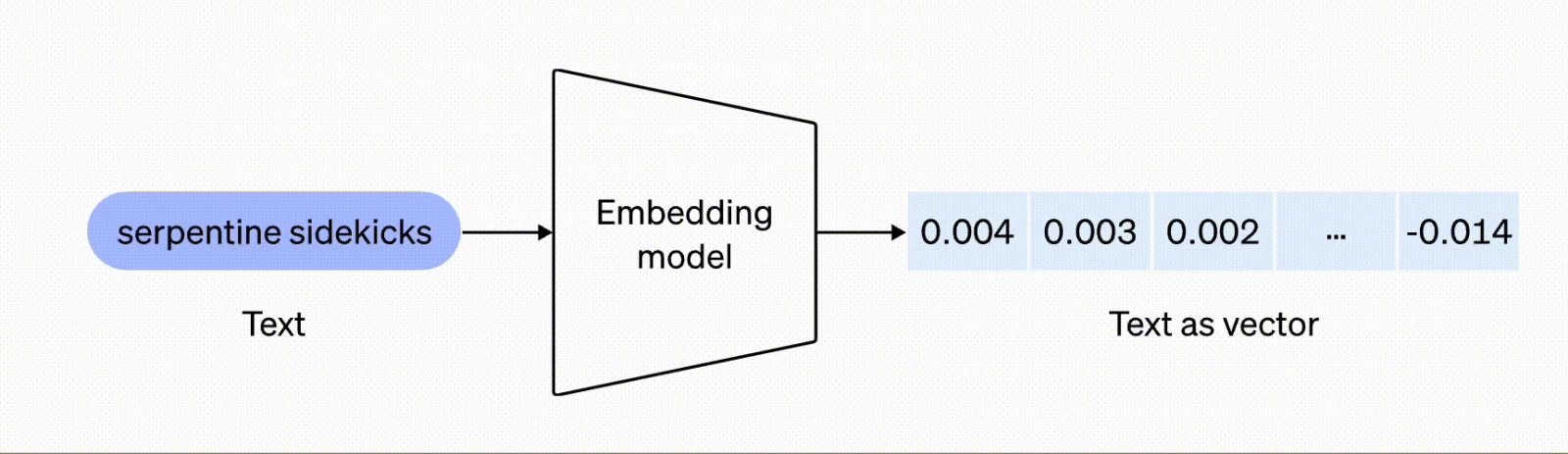
There have been many embedding models created, with ever smarter ways to capture meanings into those vectors. When you ask ChatGPT a question, under the hood, your question will automatically be converted into a numeric vector that the ChatGPT model understands.
The model will use this numeric vector to “calculate” the response. Under the hood, OpenAI also stores a vector database for your questions and responses to “remember” the conversation as you continue it in ChatGPT.
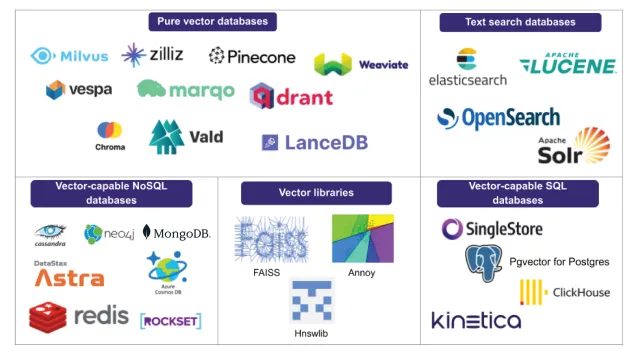
If you build an AI application with language models, you’ll need to create this vector database yourself, using a vector database of choice. Popular open-source vector databases Qdrant and Chroma can help. Simply install and use it for your AI project in Python.
Challenges in GenAI
Gen AI is the most impactful technology of the last decade, according to Gartner. However, there are still significant challenges:
- Out-of-date information: Current models like ChatGPT may not have data beyond September 2021, and updating their training data takes time.
- Lack of domain knowledge: Foundation models have general knowledge but struggle with narrow domains or specializations.
- Hallucinations: Generative models sometimes produce plausible but nonsensical outputs, misleading users.
- Poor performance on specific tasks: Generalist models excel at many tasks but may struggle with specific tasks important to certain data teams.
There are solutions to these challenges, such as retrieval augmented generation(RAG) and fine-tuning. Since you have some knowledge of vector databases, let’s discuss RAG and fine-tuning.
Retrieval augmented generation or RAG
LLMs are extensively trained on massive amount of data. Despite their impressive capabilities, one significant challenge is the potential for hallucinations, where the model might generate inaccurate or contextually irrelevant information.
When it comes to factual responses, LLMs might struggle as they lack training on specific data. So, how can we ensure that an LLMs generate relevant responses? This is where techniques like Retrieval Augmentation Generation (RAG) come handy.
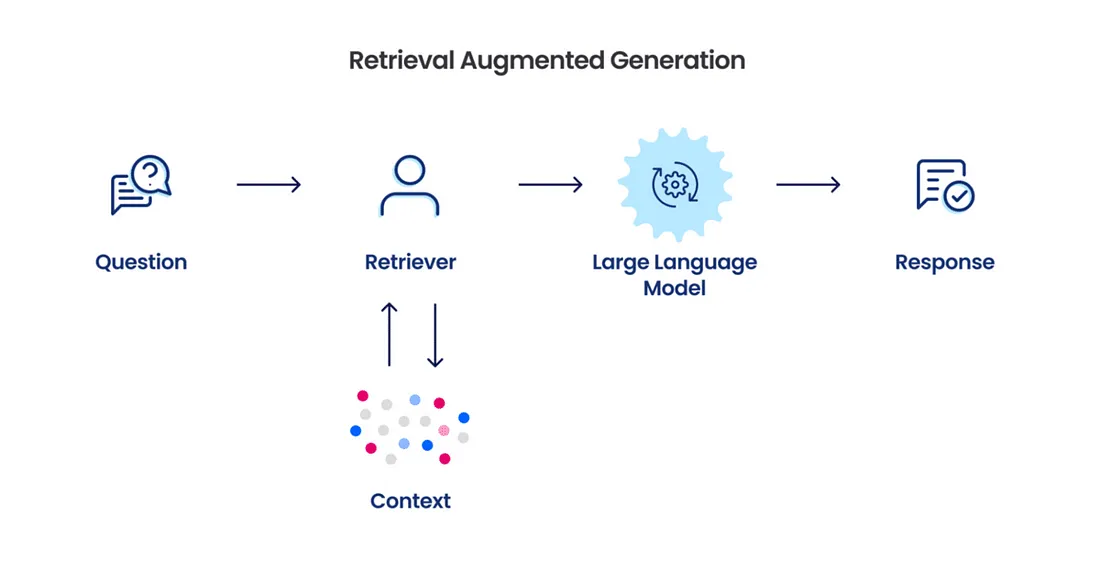
RAG augments language models with external information to produce more accurate, relevant responses. In this step, the pipeline finds information relevant to the user’s request and injects it as context. For example, Google’s Gemini (former Bard) perform traditional search queries relevant to the user’s prompt before feeding the search results as additional context to the LLM.
The input could come from:
- A vector database such as FAISS or Pinecone.
- APIs such as those for Google Maps or Stripe API.
- A search engine such as Duck Duck Go or Google.
RAG mitigates the challenge of out-of-date pre-training data by providing up-to-date information at inference time. RAG inserts an additional step between users’ requests and the generative model. This process has 3 key phases:
Information Retrieval
First, the system extracts knowledge from sources like databases and document repositories relevant to the user’s question. Converting text to vector embeddings facilitates quick machine comprehension.
Contextual Response Generation
Retrieved information gets combined with the original query into a prompt for the language model. This supplementary context grounds the model, reducing guessing and hallucination risk.
Present Final Output
Finally, the now context-aware language model generates a response incorporating the additional information which gets returned to the end user.
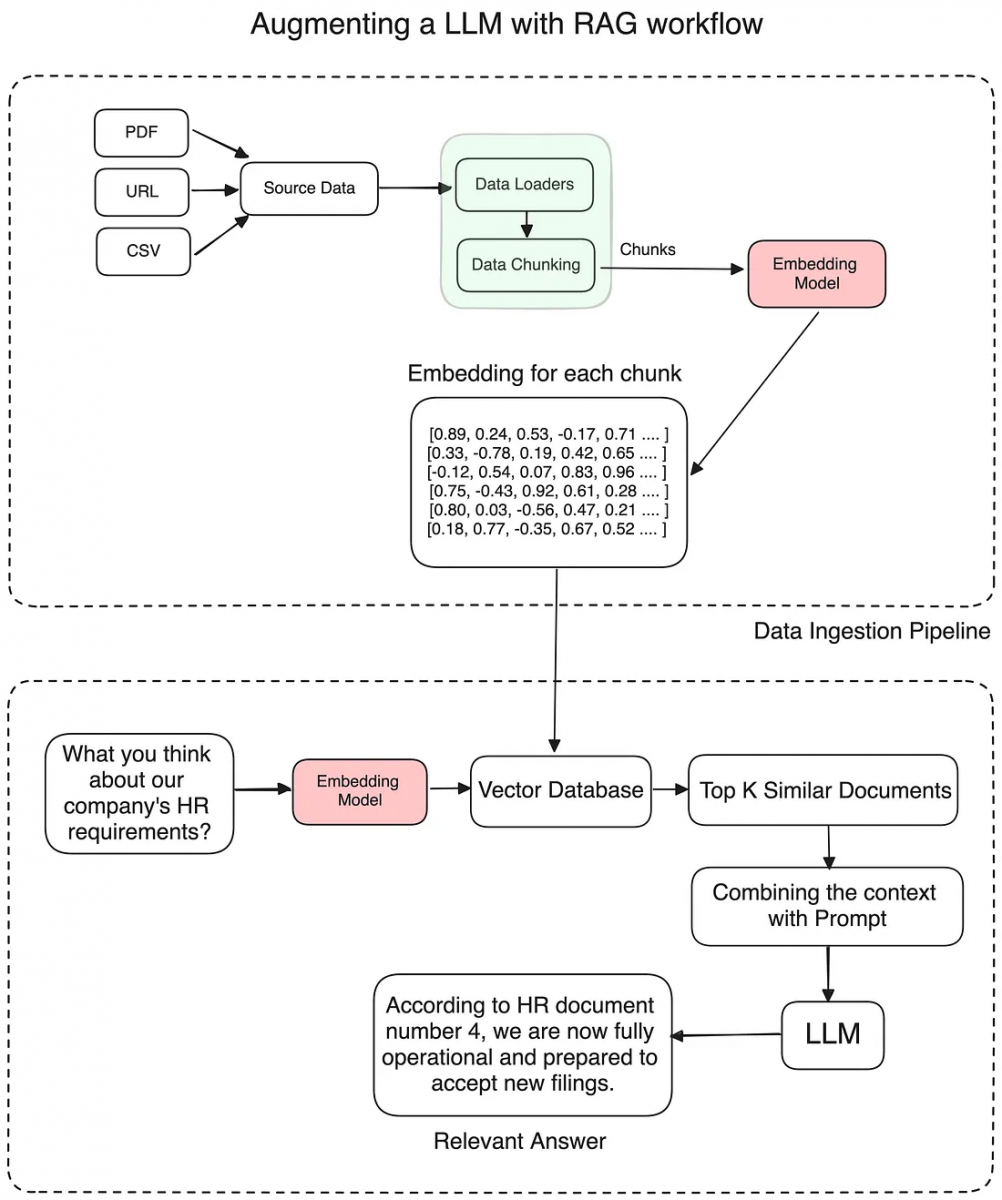
Building a Simple GenAI App using RAG:
Ingest Data: First, bring in data like text files or images.
Segmentation of data: Break up the data into smaller chunks that are easier to handle.
Vector Transformation: Turn text chunks into numeric vectors capturing semantic meaning.
Index Vectors: Save the vector representations in a database for quick retrieval.
User queries: Get a search query or question from the end user.
Semantic Search: Use the user input to find relevant vectors in the database.
Process Via Model: Send vectors through a trained AI model to generate an intelligent response.
Return Output: Present the final model-generated output to the end user.
Code and details on the above
However, RAG presents its own pitfalls. Effective RAG implementations require an efficient and effective mechanism to retrieve the correct context. Improperly implemented RAG tools can negatively impact responses by injecting irrelevant information — or, worse, it could surface sensitive information that should have been kept confidential.
Fine-tuning
Fine-tuning adapts the LLM’s weights to custom domains and tasks.
ML engineers provide prompts and expected responses to the model. The model learns the gaps between its output and the expected output, and adjusts its “attention” to specific features and patterns.
For example, if a data team wants to analyze financial documents using an LLM, they can fine-tune it using a dataset like the Financial Documents Clustering data set.
Fine-tuning improves performance in target domains and tasks and helps overcome biases, hallucination, repetition, or inconsistency.
In a previous experiment, Snorkel researchers found that a fine-tuned RoBERTa model outperformed zero-shot prompts using an off-the-shelf version of GPT-3.
The language model labeler’s baselines, accuracy, and standard error (n=3) on the test set are presented.
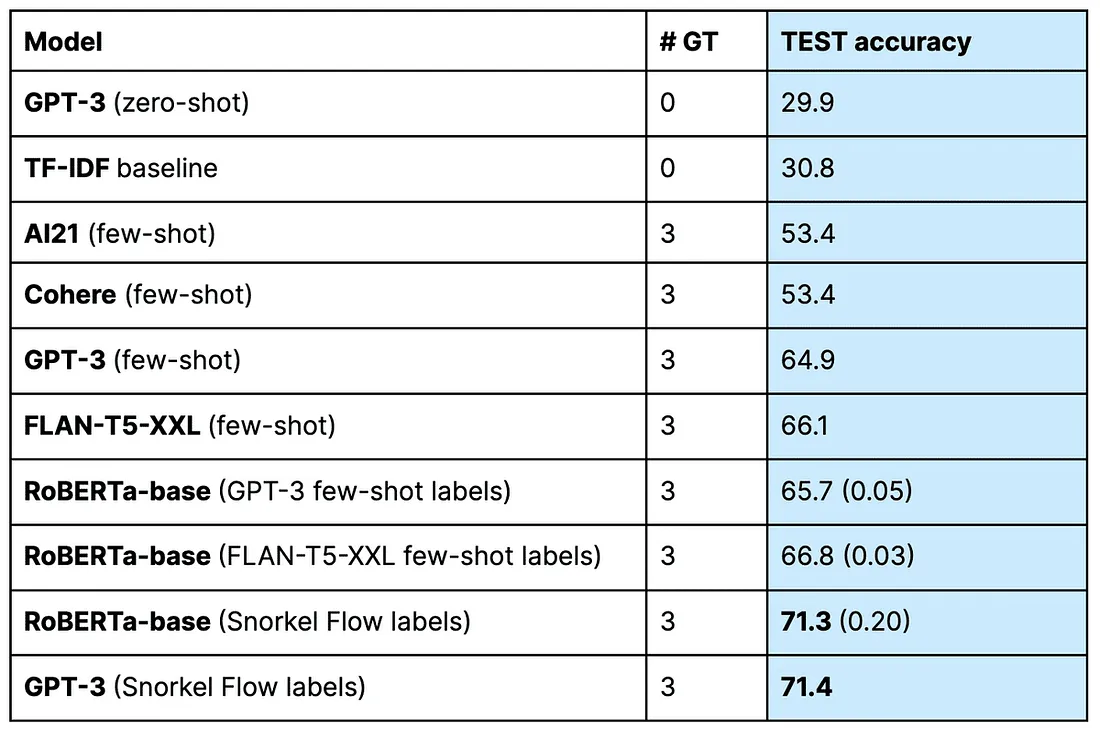
However, fine-tuning requires a large amount of labeled data, which may be scarce, noisy, or expensive to obtain. It also requires significant computational resources, which could present a significant hurdle.
Which is better, retrieval augmentation (RAG) or fine-tuning? Both.
Data science folks often debate which approach yields the best result. The answer is “both.” Neither fine-tuning nor RAG requires excluding the other, and the two approaches work better together.
To use a metaphor, a doctor needs specialty training (fine-tuning) and access to a patient’s medical chart (RAG) to make a diagnosis.
RAG vs Fine-Tuning highlights:
- Model Customization: RAG < Finetuning
Finetuning allows adjustments of LLM behavior, writing style, or specific domain knowledge based on specific tones or terms. RAG is less flexible in customization
- Interpretability: RAG > Finetuning:
RAG’s responses can be traced back to specific data sources while finetuning is like a black box, it is not always clear why the model reacts a certain way.
- Latency: RAG > Finetuning:
RAG tends to be slower because it needs to retrieve data first, which adds extra time(higher latency).
Future Trends in AI
Tracing AI’s Evolution
Understanding AI’s journey is key to predicting its future. The past decade laid the foundation for advancements in AI. Now, we’re building on this legacy, driving AI towards more complex applications.
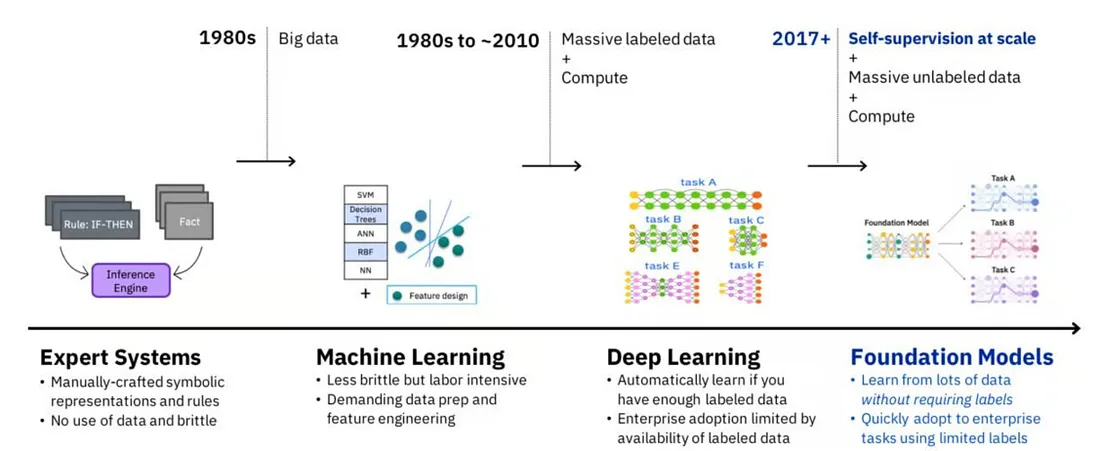
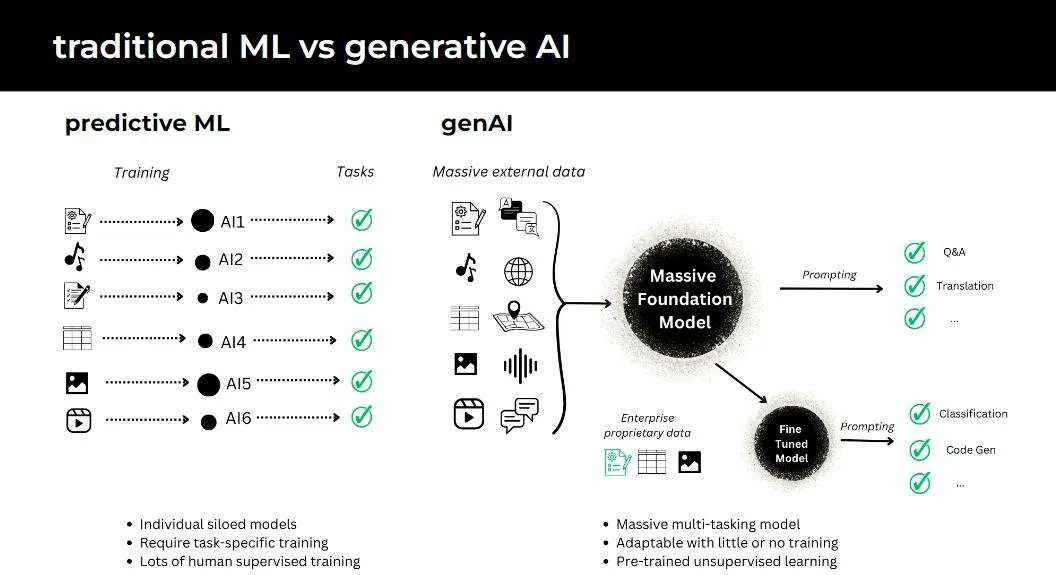
In traditional machine learning, models require task-specific training and a significant amount of human-supervised learning.
In contrast, foundation models are massive multi-tasking systems, adaptable with little or no additional training, utilizing pre-trained, self-supervised learning techniques. The limit on performance & capabilities is mostly on computing and data access (not labeling).
Synthetic Datasets
If the limit to a better model is more data, why don’t create it artificially? The rise of synthetic data is a game-changer. It’s about creating artificial datasets that can train AI without compromising privacy or relying on scarce real-world data. It is set to revolutionize fields from healthcare to autonomous driving, making AI training more accessible, ethical, and comprehensive.
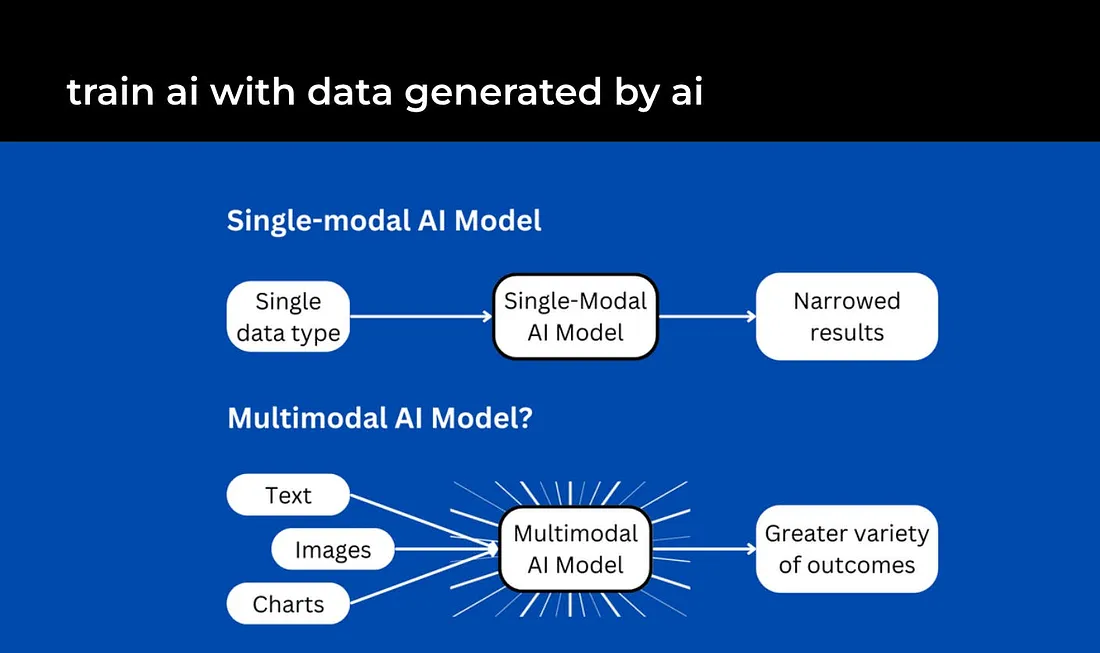
Multimodality
Integrating multiple data types like text, images, video, and audio will enable more seamless understanding of multifaceted concepts. As AI grows adept across modalities, expect smarter assistants and more immersive experiences. This holistic approach will deepen AI’s integration into daily life, from smarter virtual assistants to more intuitive educational tools.
Reinforcement Learning
Allowing systems to optimize behaviors through trial-and-error and rewards bypasses the limitations of static training data. Reinforcement learning has surpassed human performance in games like Go and may be applied to scientific research or robotic control. It is an important approach that is distinct from models like transformers.
Automating AI Development
Automating ML tasks like architectural search, hyperparameter tuning, and data pipeline management will accelerate innovation. Frameworks enabling recursive self-improvement cycles signal AI fast approaching the flexibility of human researchers and engineers in conducting experiments.
Beyond Chats
While AI Chat Platforms have made a huge impact, the future extends far beyond text. Expect AI that can seamlessly interact across various formats, offering richer, more immersive experiences. Whether it’s in education or entertainment AI will engage us in more meaningful, dynamic ways.
Mastering Gen AI dev stack is not just about understanding the current capabilities of AI, but also about envisioning and contributing to its future. As we push the boundaries of what is possible, the role of AI in our lives is set to become even more integral and transformative.